In this page, I will use keras to fit three different neural network models, LSTM, RNN, and GRU, to predict the weekly sales of type A stores, which we have been already familiar after preceding tabs. The goal in this page is to compare the performances between these three deep learning models and also to find out whether these deep learning methods outperform traditional time series models, such as ARIMA and SARIMA.
1 Data preparation
First of all, import relevant packages and read the csv file.
Code
import warningswarnings.filterwarnings("ignore")import pandas as pdimport numpy as npfrom keras.models import Sequentialfrom keras.layers import Dense, SimpleRNN,LSTM,GRUfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.metrics import mean_squared_errorimport matplotlib.pyplot as pltimport tensorflow as tf
Code
df=pd.read_csv("A_sales.csv")df=df.iloc[:,[0,1]]X=np.array(df["avg"].values.astype('float32')).reshape(df.shape[0],1)print("Shape of X:",X.shape)
Shape of X: (143, 1)
2 Visualize the time series
Code
import plotly.io as piopio.renderers.default ="plotly_mimetype+notebook_connected"import plotly.express as px# UTILITYdef plotly_line_plot(t,y,title="Plot",x_label="t: time (weeks)",y_label="y(t): Weekly sales"):# GENERATE PLOTLY FIGURE fig = px.line(x=t[0],y=y[0], title=title, render_mode='SVG') # ADD MOREfor i inrange(1,len(y)):iflen(t[i])==1:#print(t[i],y[i]) fig.add_scatter(x=t[i],y=y[i])else: fig.add_scatter(x=t[i],y=y[i], mode='lines') fig.update_layout( xaxis_title=x_label, yaxis_title=y_label, template="plotly_white", showlegend=False ) fig.show()t=[*range(0,len(X))]plotly_line_plot([t],[X[:,0]],title="Weekly sales per week since 2010-02")
3 Data splitting and re-formatting
Use the first 80% data as training set and last 20% as test set.
Code
# Parameter split_percent defines the ratio of training examplesdef get_train_test(data, split_percent=0.8): scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data).flatten() n =len(data)# Point for splitting data into train and test split =int(n*split_percent) train_data = data[range(split)] test_data = data[split:]return train_data, test_data, datatrain_data, test_data, data = get_train_test(X)print("training shape:",train_data.shape)print("test shape:",test_data.shape)
training shape: (114,)
test shape: (29,)
Visualize the training-test splitting:
Code
# SINGLE SERIES t1=[*range(0,len(train_data))]t2=len(train_data)+np.array([*range(0,len(test_data))])plotly_line_plot([t1,t2],[train_data,test_data],title="Visualization for training-test splitting")
Now, it is important to re-format the data for keras to use. The ‘time_steps’ for this data is set as 4.
Code
# PREPARE THE INPUT X AND TARGET Ydef get_XY(dat, time_steps,plot_data_partition=False):global X_ind,X,Y_ind,Y #use for plotting later# INDICES OF TARGET ARRAY# Y_ind [ 12 24 36 48 ..]; print(np.arange(1,12,1)); exit() Y_ind = np.arange(time_steps, len(dat), time_steps);#print(Y_ind); exit() Y = dat[Y_ind]# PREPARE X rows_x =len(Y) X_ind=[*range(time_steps*rows_x)]del X_ind[::time_steps] #if time_steps=10 remove every 10th entry X = dat[X_ind];#PLOTif(plot_data_partition): plt.figure(figsize=(15, 6), dpi=80) plt.plot(Y_ind, Y,'o',X_ind, X,'-'); plt.show();#RESHAPE INTO KERAS FORMAT X1 = np.reshape(X, (rows_x, time_steps-1, 1))# print([*X_ind]); print(X1); print(X1.shape,Y.shape); exit()return X1, Y#PARTITION DATAp=5# simpilar to AR(p) given time_steps data points, predict time_steps+1 point (make prediction one month in future)testX, testY = get_XY(test_data, p)trainX, trainY = get_XY(train_data, p)print("re-formatted test X shape:",testX.shape)print("re-formatted train X shape:",trainX.shape)print("re-formatted test Y shape:",testY.shape)print("re-formatted train Y shape:",trainY.shape)
re-formatted test X shape: (5, 4, 1)
re-formatted train X shape: (22, 4, 1)
re-formatted test Y shape: (5,)
re-formatted train Y shape: (22,)
Visualization of re-formatted data:
Code
## Build list tmp1=[]; tmp2=[]; tmp3=[]; count=0for i inrange(0,trainX.shape[0]):# tmp1.append() tmp1.append(count+np.array([*range(0,trainX[i,:,0].shape[0])])) tmp1.append([count+trainX[i,:,0].shape[0]]);#print(([count+trainX[i,:,0].shape[0]]))# tmp1.append([count+trainX[i,:,0].shape[0]+1]) tmp2.append(trainX[i,:,0]) tmp2.append([trainY[i]]);#print([trainY[i]])# tmp2.append([trainY[i]]) count+=trainX[i,:,0].shape[0]+1plotly_line_plot(tmp1,tmp2,title="Weekly sales per week since 2010-02")
It is clear that this data has been already transformed to be utilized for keras LSTM.
4 Model training and comparison
4.1 LSTM model
Customize the parameters and create the model:
Code
#USER PARAMrecurrent_hidden_units=3epochs=60f_batch=0.2#fraction used for batch sizeoptimizer="RMSprop"validation_split=0.2
Code
from tensorflow.keras import regularizers#CREATE MODELmodel = Sequential()#COMMENT/UNCOMMENT TO USE RNN, LSTM,GRUmodel.add(LSTM(# model.add(SimpleRNN(# model.add(GRU(recurrent_hidden_units,return_sequences=False,input_shape=(trainX.shape[1],trainX.shape[2]), # recurrent_dropout=0.8,recurrent_regularizer=regularizers.L2(1e-1),activation='tanh') ) #NEED TO TAKE THE OUTPUT RNN AND CONVERT TO SCALAR model.add(Dense(units=1, activation='linear'))# COMPILE THE MODEL model.compile(optimizer=optimizer, loss=tf.keras.losses.MeanSquaredError())model.summary()
import randomrandom.seed(100)#TRAIN MODELhistory = model.fit(trainX, trainY, epochs=epochs, batch_size=int(f_batch*trainX.shape[0]), validation_split=validation_split, # BEING "SLOPPY WITH CROSS VALIDATION" HERE FOR TIME-SERIESverbose=0)
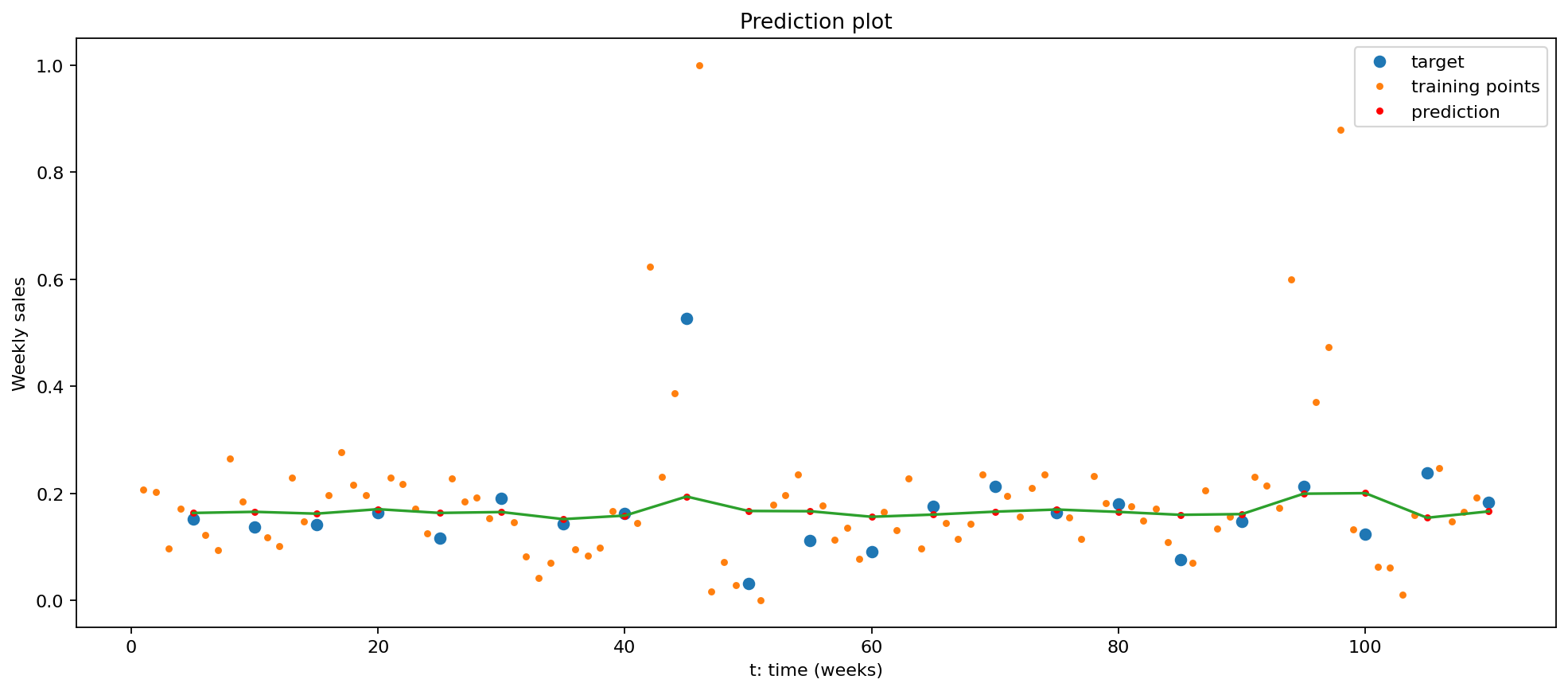
The red points and green line displays the prediction of the model, while orange and blue points are original training points. This plot shows that the LSTM model dose not fit the data very well.
4.2 SimpleRNN model
First create the model using keras:
Code
from tensorflow.keras import regularizers#CREATE MODELmodel = Sequential()#COMMENT/UNCOMMENT TO USE RNN, LSTM,GRU# model.add(LSTM(model.add(SimpleRNN(# model.add(GRU(recurrent_hidden_units,return_sequences=False,input_shape=(trainX.shape[1],trainX.shape[2]), # recurrent_dropout=0.8,recurrent_regularizer=regularizers.L2(1e-1),activation='tanh') ) #NEED TO TAKE THE OUTPUT RNN AND CONVERT TO SCALAR model.add(Dense(units=1, activation='linear'))# COMPILE THE MODEL model.compile(optimizer=optimizer, loss=tf.keras.losses.MeanSquaredError())model.summary()
#TRAIN MODELhistory = model.fit(trainX, trainY, epochs=epochs, batch_size=int(f_batch*trainX.shape[0]), validation_split=validation_split, # BEING "SLOPPY WITH CROSS VALIDATION" HERE FOR TIME-SERIESverbose=0)
WARNING:tensorflow:5 out of the last 9 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f958a6b4040> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
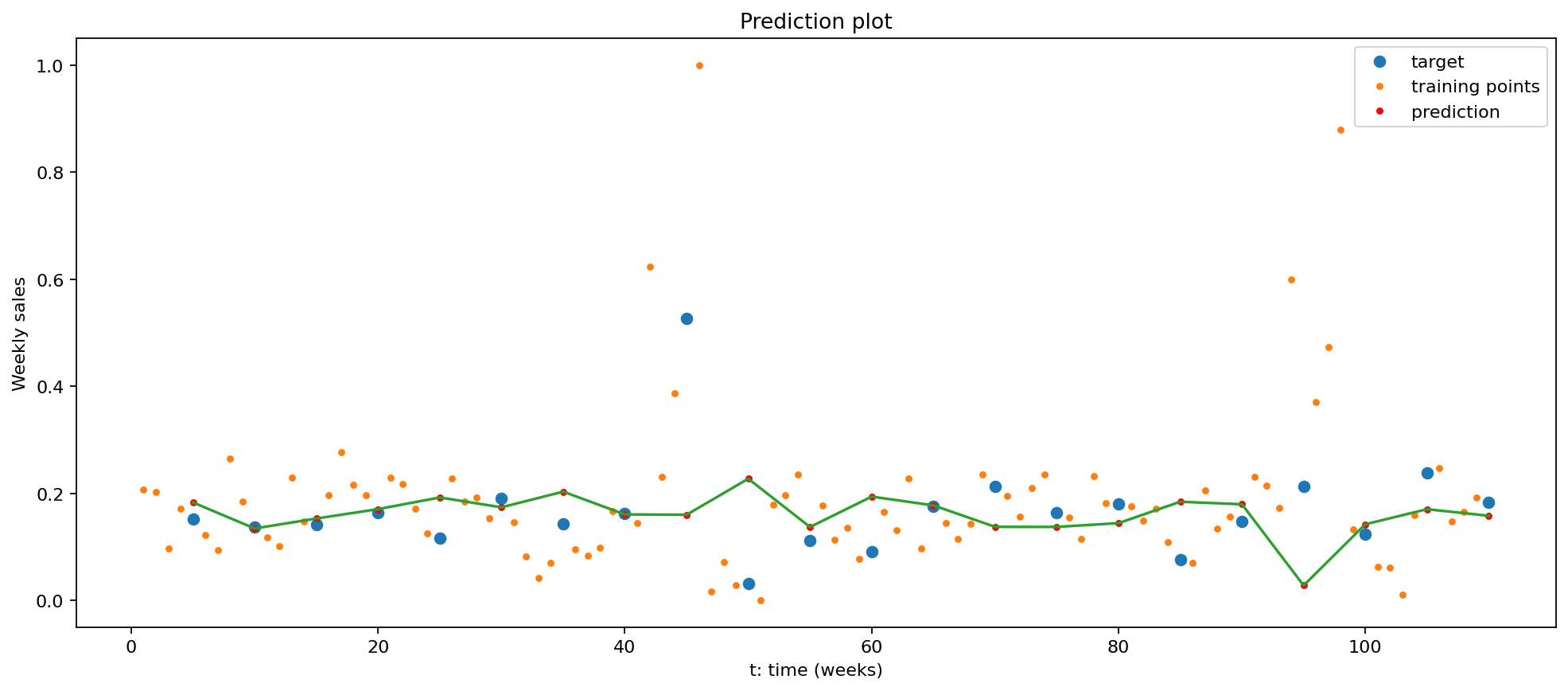
It is noticed that this SimpleRNN model does not perform perfectly either. It captures some of the data pattern but does not fit the crest during the end of every year well.
4.3 GRU model
Finally, let’s consider a GRU model.
Code
from tensorflow.keras import regularizers#CREATE MODELmodel = Sequential()#COMMENT/UNCOMMENT TO USE RNN, LSTM,GRU# model.add(LSTM(# model.add(SimpleRNN(model.add(GRU(recurrent_hidden_units,return_sequences=False,input_shape=(trainX.shape[1],trainX.shape[2]), # recurrent_dropout=0.8,recurrent_regularizer=regularizers.L2(1e-1),activation='tanh') ) #NEED TO TAKE THE OUTPUT RNN AND CONVERT TO SCALAR model.add(Dense(units=1, activation='linear'))# COMPILE THE MODEL model.compile(optimizer=optimizer, loss=tf.keras.losses.MeanSquaredError())model.summary()
#TRAIN MODELhistory = model.fit(trainX, trainY, epochs=epochs, batch_size=int(f_batch*trainX.shape[0]), validation_split=validation_split, # BEING "SLOPPY WITH CROSS VALIDATION" HERE FOR TIME-SERIESverbose=0)
WARNING:tensorflow:6 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f958a70b7f0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
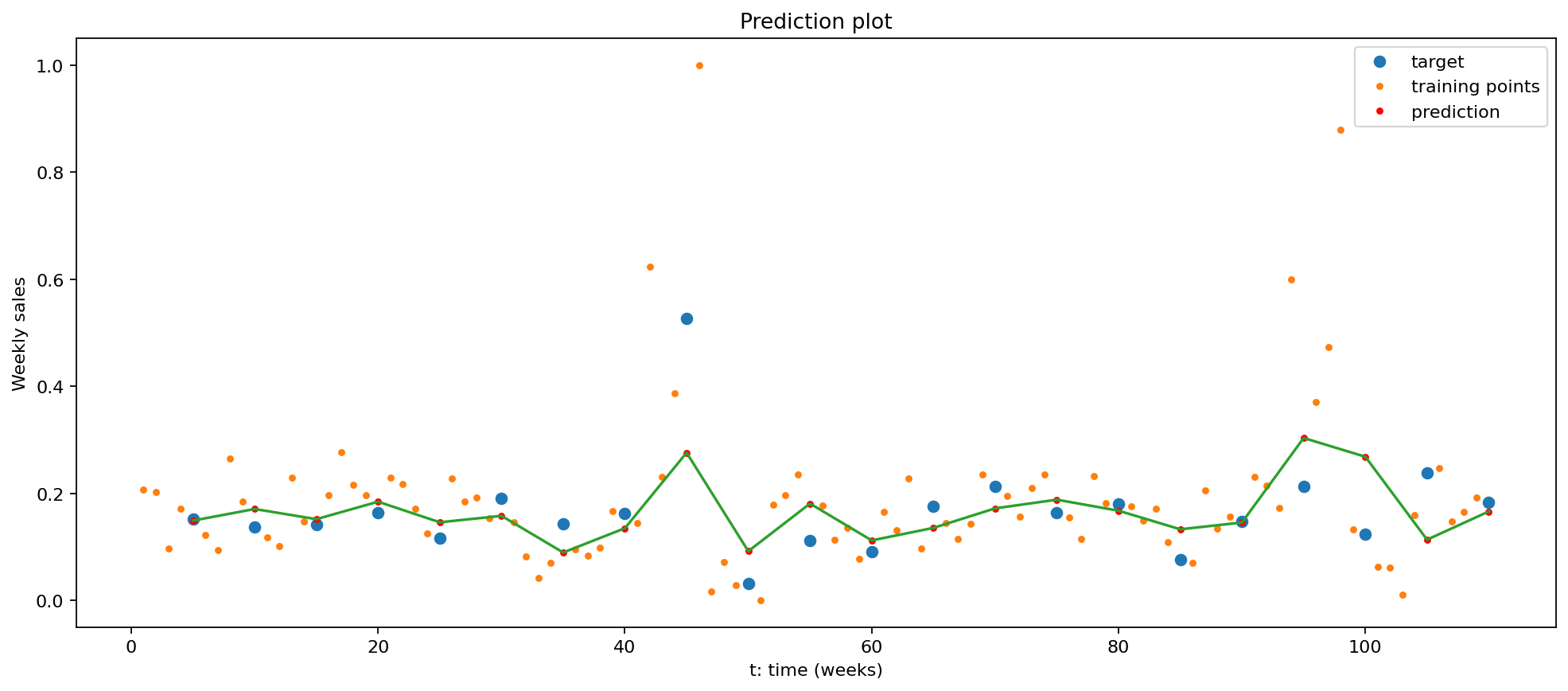
According to the plots above, this GRU model generates relatively better predictions for this weekly sales data. However, it is still not very satisfactory.
After fitting these three deep learning models on this data, we can notice that all these three achieve relatively small RMSE on the test set after training for 60 epochs. Nevertheless, the parity plot and prediction plot show that these three methodologies do not fit the data perfectly. Besides, since I have applied L2 regularization for all three models, we do not meet overfitting problems. The models tend to have slightly higher bias but lower variance due to the regularization. Additionally, the test set include weekly sales data for nearly 7 months, and these three models all reach a small RMSE on the test data, which suggests that these deep learning models are able to predict the weekly sales of near future with a moderately good accuracy.
5 Conclusion
In the preceding tabs, we have discussed about using traditional time series models to forecast the Walmart weekly sales. Since we have also tried deep learning methodologies to do the same task in this page, we are able to draw some conclusions on the performances of different models for this data. Based on the RMSE on test data, these three deep learning methods obviously outperform simple time series model, like ARMA and ARIMA, which could not capture the seasonality within this weekly sales data. However, SARIMA and more complicated SARIMAX models fit the seasonal components quite well and perform much better than other methods that we have tried, including the neural networks.
One possible reason why deep learning methods do not perform so well is the small scale of this data. As mentioned before, this data only contains weekly sales of Walmart stores from 2010 to 2012. Since the seasonal period is one year, the data has just three periods. It is known that deep learning models usually rely on data with relatively large size. Therefore, these models might struggle with this small sample of data. Specifically, the weekly sales by the end of each year always reach the crest due to Thanksgiving and Christmas. However, these extremely high sales data only appears in four or five weeks, which is too short for the deep learning method, like LSTM, to learn the special data pattern, because the time steps of this model itself is four weeks.